
The study of collective action can benefit greatly from big data. Collective action is the study of how large numbers of individuals engage each other to accomplish a common task; big data illuminate how large numbers of individuals engage each other over time. Yet these data have yet to show how they can improve our understanding of protests. Protests are one of the hardest collective action problems: large groups of individuals with little prior contact must come together and coordinate their behavior in risky situations for public goals. My research starts to show how, carefully used, big data generate new insights into protest processes.
If social scientists have been stuck looking for their keys under a streetlight, “big data” constitutes an upgrade to using stadium lights. While the term can refer to data generated through a number of processes – the National Security Agency consumes 29 petabytes of data per day, the European Organization for Nuclear Research (CERN) produces 1 petabyte per day, and Facebook 600 terabytes – its most common understanding is of data generated through large numbers of individuals providing their data to companies in return for a service. (I therefore prefer the term “user-generated data” but will stick to “big data” for consistency.) These very large datasets allow researchers to develop new theories and test competing ones against each other, the bedrock of the scientific enterprise.
Having orders of magnitude more data provide 3 key advantages. Researchers can now observe more people (1) over long periods (2) at narrow time intervals (3). These data can reflect activity as it happens: they reveal how mood patterns change over time (Golder and Macy 2011), people share information in a crisis (Starbird 2010, Cassa et al. 2013), and variations in unemployment rates (Llorente et. al 2014). They can also predict future events: flu outbreaks (Achrekar et al. 2012, Davidson et al. 2015), stock market changes (Bollen et al. 2011), crime (Gerber 2014), and sports outcomes (Sinha et al. 2013).
In my dissertation, I show how careful use of big data can advance our knowledge of protests. To understand how people coordinate, I analyze 13.7 million geolocated tweets from 16 Middle East and North African countries from 2010 and 2011. These tweets were selected from Twitter’s 10% stream, meaning they were not chosen for hashtags (Mocanu et al. 2012). Not selecting on hashtags has 3 advantages: I see discourse occurring outside of those found through specific hashtags, find hashtags that I would not have known were important ahead of time, and have a denominator with which to normalize each country’s measures. I then create a non-parametric measure of coordination, a Gini measure for hashtags, and show that coordination correlates with protest up to 3 days in the future. Figure 1 shows this result.
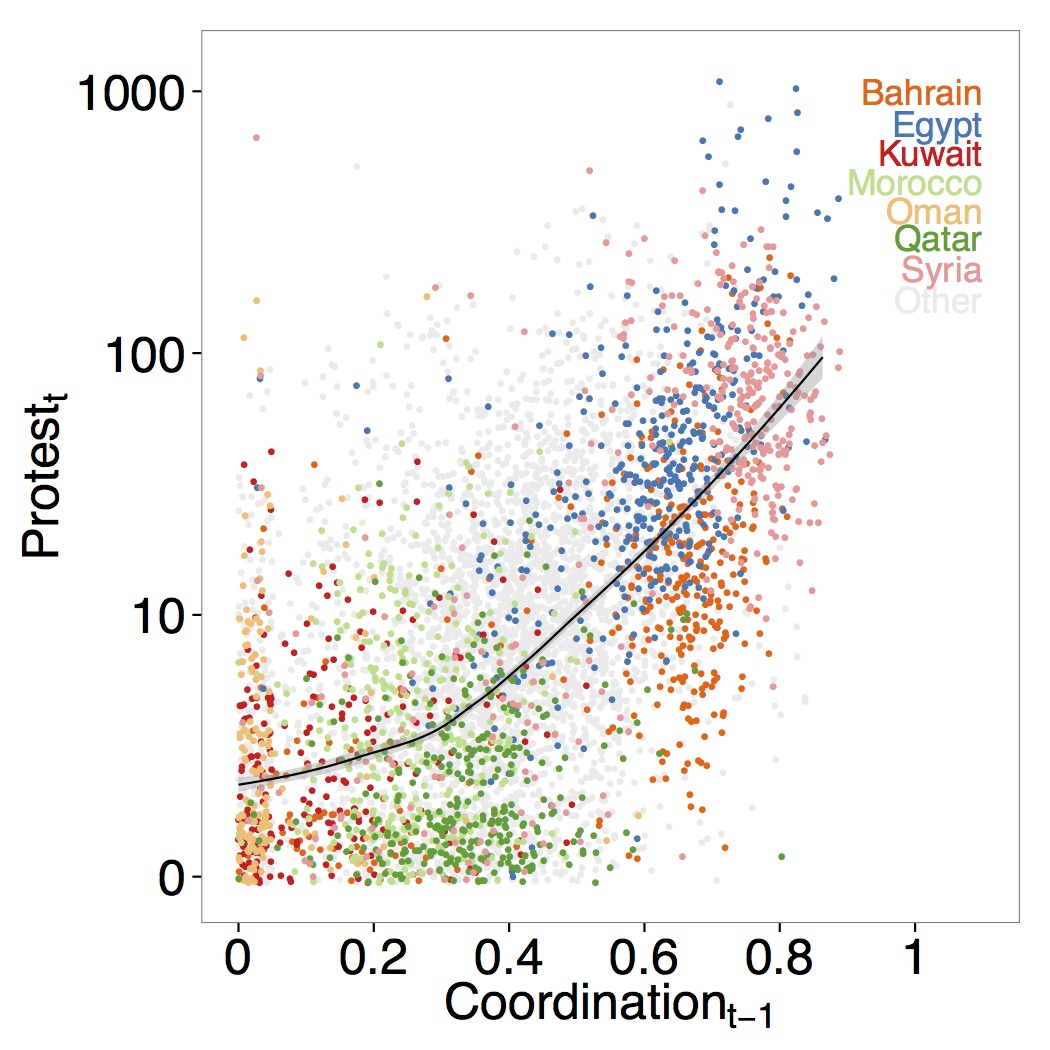
There are 6 reasons, derived from methodological innovations not previously used in social movement studies using social media data, to have confidence in these results. First, each tweet originates from a user in one of the countries in the study, so the result is not driven by foreigners who just happen to talk about the countries’ events. Second, because individuals use Twitter to attract international attention to domestic events, I rerun my models using only Arabic tweets and find the result is not driven by English tweets. Third, the measure of coordination does not rely on predefined hashtags, allowing it to detect the most used hashtags as they change. The results are therefore robust to changing rhetorical frames and events over long periods of time. Fourth, not selecting on hashtags means knowing how many tweets per day come from each country, allowing me to control for spikes. Fifth, since I do not select on hashtags, I also know how many tweets per day come from each country, allowing me to control for spikes. Around any major event, there is a spike of tweets, especially of the hashtags most common to those events; this pattern leads researchers to conclude that “X was used more” without knowing if it was used more just because there were all tweets. Conclusions reached without controlling for overall Twitter activity therefore risk finding spurious correlations. Sixth, not relying on hashtags means I can create machine learning models to detect patterns of communication that might escape traditional algorithmic analysis.
In another dissertation chapter, I show how Twitter can give near real-time portraits of public opinion in contentious environments. Using almost 5 million tweets with GPS coordinates that were extracted from Twitter’s 1% stream, I, along with Jesse Driscoll, developed dictionaries to distinguish pro-Yanukovych tweets from anti-Yanukovych ones. Once we used a human coder to verify the dictionaries accurately identified tweets in those categories, we show that the rhetoric differs sharply across Ukraine.
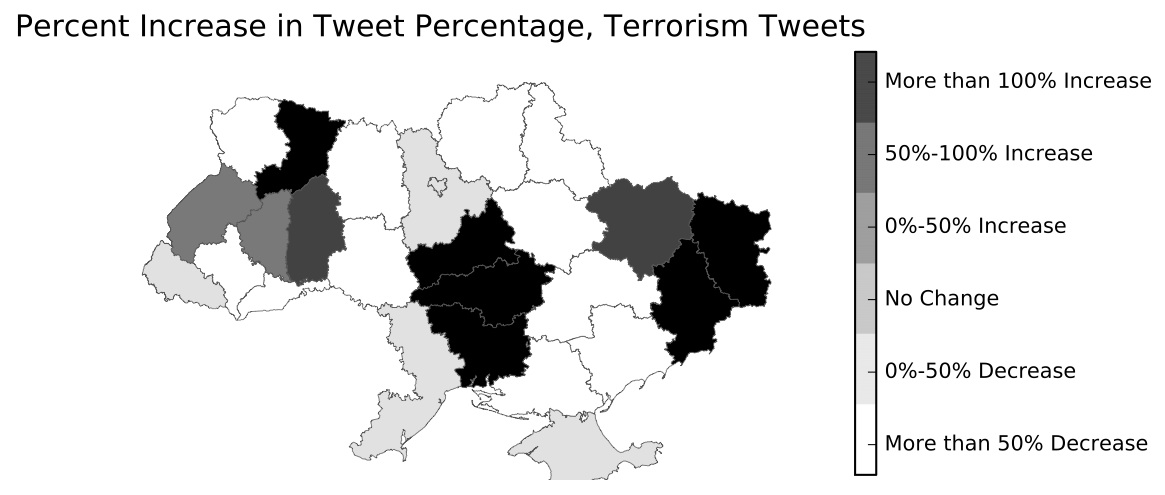
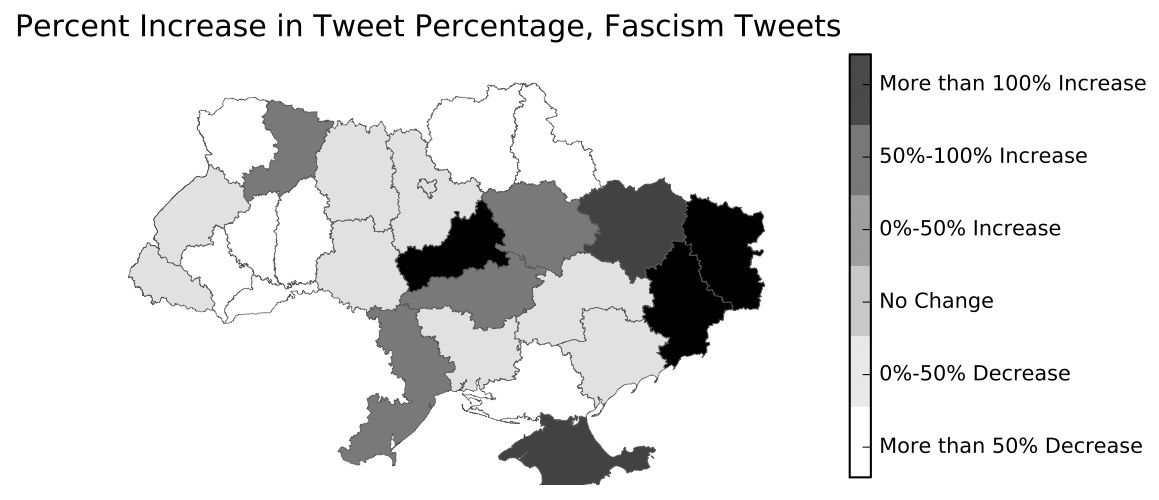
For all the excitement surrounding big data, they are not a panacea (Tufekci 2014). The modal big data paper selects on the dependent variable (usually hashtag use), is unclear about who exactly is being sampled (using “#tahrir” does not mean you are there, in Cairo, or even in Egypt), and has trouble analyzing many forms of online communication. These research design problems cause scholars to over-interpret levels of anti-regime sentiment (Barbera and Metzger 2013), the role of influential individuals (Bailon et al. 2011), and the way social media are used by people possibly involved in protest (Aday et al. 2012).
To productively use Twitter to understand social movements, researchers should undertake the following steps. First, tweets should be downloaded in real time to allow the researcher to understand dynamics before an event occurs. Second, tweets should not be selected on hashtag; one can download tweets based on language or location, and selecting on those is acceptable because they still provide a denominator. Downloading in real time, agnostic to the event in question, is the best way to avoid selecting on hashtags. Third, all statistics need to be normalized, as the number of users and tweets grows daily. Fourth, more detailed coding allows the user to see beyond obvious Twitter behaviors: creating dictionaries, researching individual accounts, and creating supervised topic models all extend the power of social media analysis.
Big data are here to stay, so we must learn how to productively harness them. Yet they are still observational, meaning they do not solve problems of endogeneity or omitted variables. While they allow us to quantify context with more precision than ever before, substantive knowledge is still required to properly address issues of causality and representativeness. Even with stadium lights, there remain many shadows.
